My experience attending and presenting at CVPR22
The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) is a premier international conference held every year in the US. The 2022 CVPR is held in New Orleans, Louisiana, and I am fortunate enough to attend and present at the event.
Conference Format
This year’s CVPR is a hyprid event. It’s the first CVPR happening in-person since the pandemic. The in-person conference lasts 6 days from June 19 to 24: Sunday to Monday are workshops, and Tuesday to Friday is the main conference. It’s a huge conference, even though it lasts about a week, there are lots of things happening in parallel. There are about 30 to 40 all-day workshops going in parallel, and three oral sessions going in parallel in the main conference. It’s impossible to go to everything, so everyone has to choose what they are most interested in. There’s an additional virtual poster session happens one-week after the main conference, and the in-person poster presenters are encouraged to sign up as well.

The event takes place at the Ernest N. Morial Convention Center at downtown New Orleans by the Mississippi river bank. It’s an enormous conference center, even 5,600 people looks sparse.
For the main conference paper presentation, there are two formats this year: oral and poster. Oral presentations has 5 minutes, and posters last for one morning or afternoon. The oral presenters also attend the poster sessions, so people have more chances to interact with the authors.
Sunday Workshops
I jumped between a few workshops for keynotes and full paper presentations. Here I select a few papers and talks that are interesting to me and offer some thoughts and digestion.
NAS Workshop
Workshop link: link
Evolving Search Space for Neural Architecture Search
- Paper link: cvf.com
- Published in ICCV21, The University of Sydney
Neural architecture search automates the process of handcrafting neural nets, but the quality of searched candidates are affected by the search space, which again is handcrafted. Plus, enlarging the search space does not produce better candidates, instead, it is unbeneficial or even detrimental to existing NAS methods.
This work proposes to evolve the search space by repeating two steps: 1) search an optimized space from the search space subset, 2) re-fill this subset from a larger pool of operations that haven’t been traversed. Their method yields better performance and lower FLOPs comparing against NAS methods without distillation and weight pruning.
Dynamic Neural Network Workshop
Workshop link: link
More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity
- By Prof. Atlas Wang, UT Autstin
- Slides: google drive
Why is transformer better than convolution on visual tasks? On the one hand, CNNs have inductive biases like local smoothness, hierarchical representations, translation invariance. Transformers don’t have these inductive bias, and that allows transformers to learn better representations. On the other, and perhaps more importantly, transformers have global reception field since day-one. ViT divides images into patches and trains global attention across patches.
Is it possible to scale up convolution’s kernel size to have a large reception field? RepLKNet (Ding et al, 2022) shows that large kernels are effective for boosting CNN’s performance. However, applying RepLKNet’s reparameterization trick on ConvNeXT makes accuracy drop because local details are lost. The solution to scale convolution kernels beyond 51x51 is using sparsity.
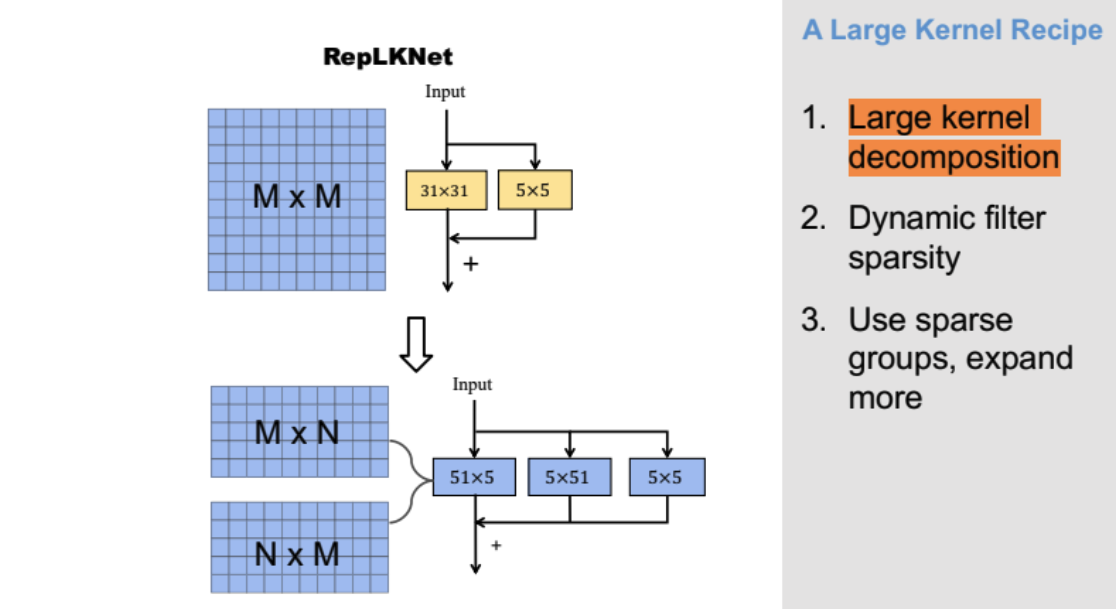
The recipe is:
- Large kernel decomposition: decompose a
MxMconvolution to three parallel branches of convolution layers with kernel sizeMxN,NxM, and5x5. - Dynamic feature sparsity: dynamically select a subset of kernel parameters in each train iteration (dropout is a random dynamic sparsity) by turning off kernel elements with large gradients.
- Use sparse groups: do step 2 by channel-wisely.
Q&A
- Since large convolution kernels give us large reception field, does that mean we don’t have to rely on stacking lots of layers to get global reception field?
The answer is yes, they observe that CNNs with larger kernels requires less layers to achieve the same level of performance. - How regular is the sparse pattern?
The sparse pattern is elementwise and not regular. But the sparse pattern eventually converges during training, and is fixed during inference.
Towards Robust and Efficient Visual Systems via Dynamic Representations
- By Xin Wang from Microsoft Research
- Slides: google drive
We need a new type of visual attention model to improve robustness
- Transformer’s self attention is not robust: e.g. when noise is added to the image.
- It also doesn’t follow the human eye’s fixation (attention).
- Human attention has two important features: recurrency and sparsity
- Formulating this idea in NN: feedforward nn with recurrency + a sparse reconstruction layer
- In this formulation, self-attention is a special case.
- The result NN is robust to noise, compression, weather. The attentiond visualization also aligns with human eye fixation (how hasn’t anyone thought this before?).
SkipNet: dynamic routing – to change network architecture at runtime
- Different images have different complexity, they should not go through the same depth of feature extraction.
- Each layer has a gate to decide if the next layer should execute.
- Using RL agent for the decision, with pretrained feature extractor.
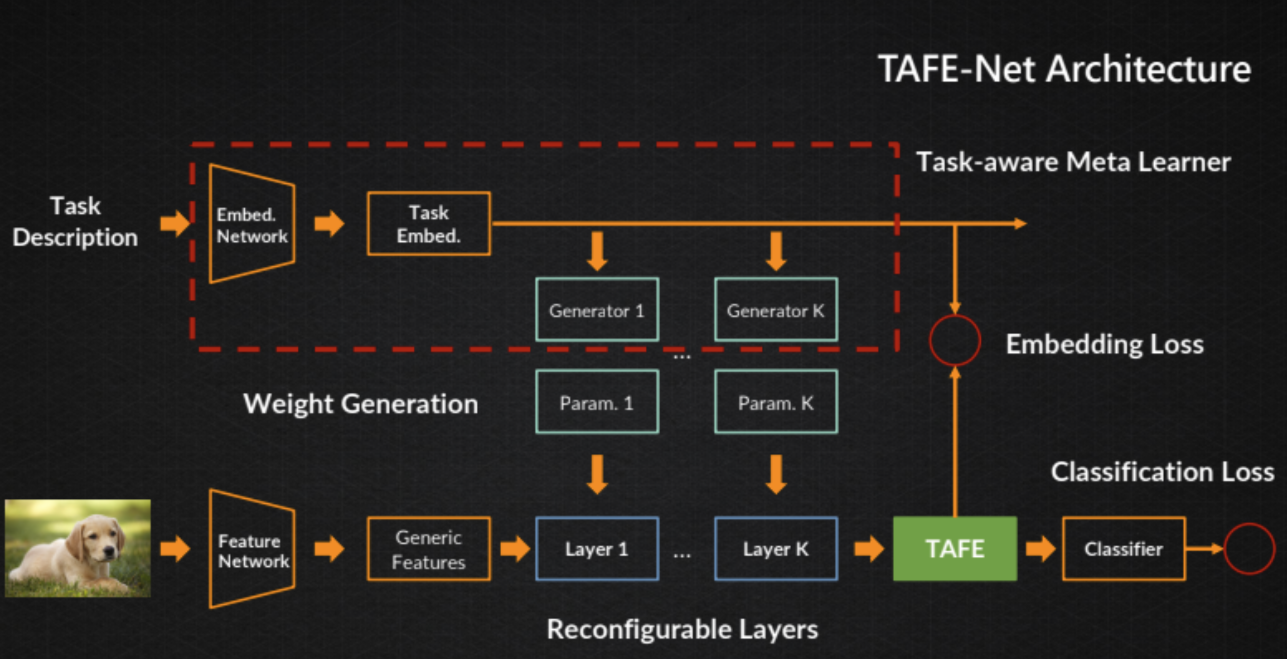
Zero-shot knowledge generalization
- Imagine “red elephant”. You have never seen one but you know what’s “red” and what’s “elephant”, so you can imagine that.
- Proposes “task-aware feature embedding”
ScanNet Indoor Scene Understanding Challenge
Workshop link: website
Towards Data-Efficient and Continual Learning for 3D Scene Understanding
- Prof. Gim Hee Lee from NUS
- Data efficiency: using 2D image labels to train 3D bounding box detection on point cloud data.
- Continual learning: knowledge distillation and solving catastrophic forgetting issues.
- Three consistency losses for knowledge distillation: alignment-aware, class-aware, and size-aware losses.
- Use knowledge distillation to solve forgetting old classes.
- The relevant paper is: Static-Dynamic Co-teaching for Class-Incremental 3D Object Detection, AAAI 22. link
Monday Workshops
Efficient Deep Learning for Computer Vision Workshop
Host: Bichen Wu, Research Scientist at Meta
Link: website
Efficient and Robust Fully-attentional Networks
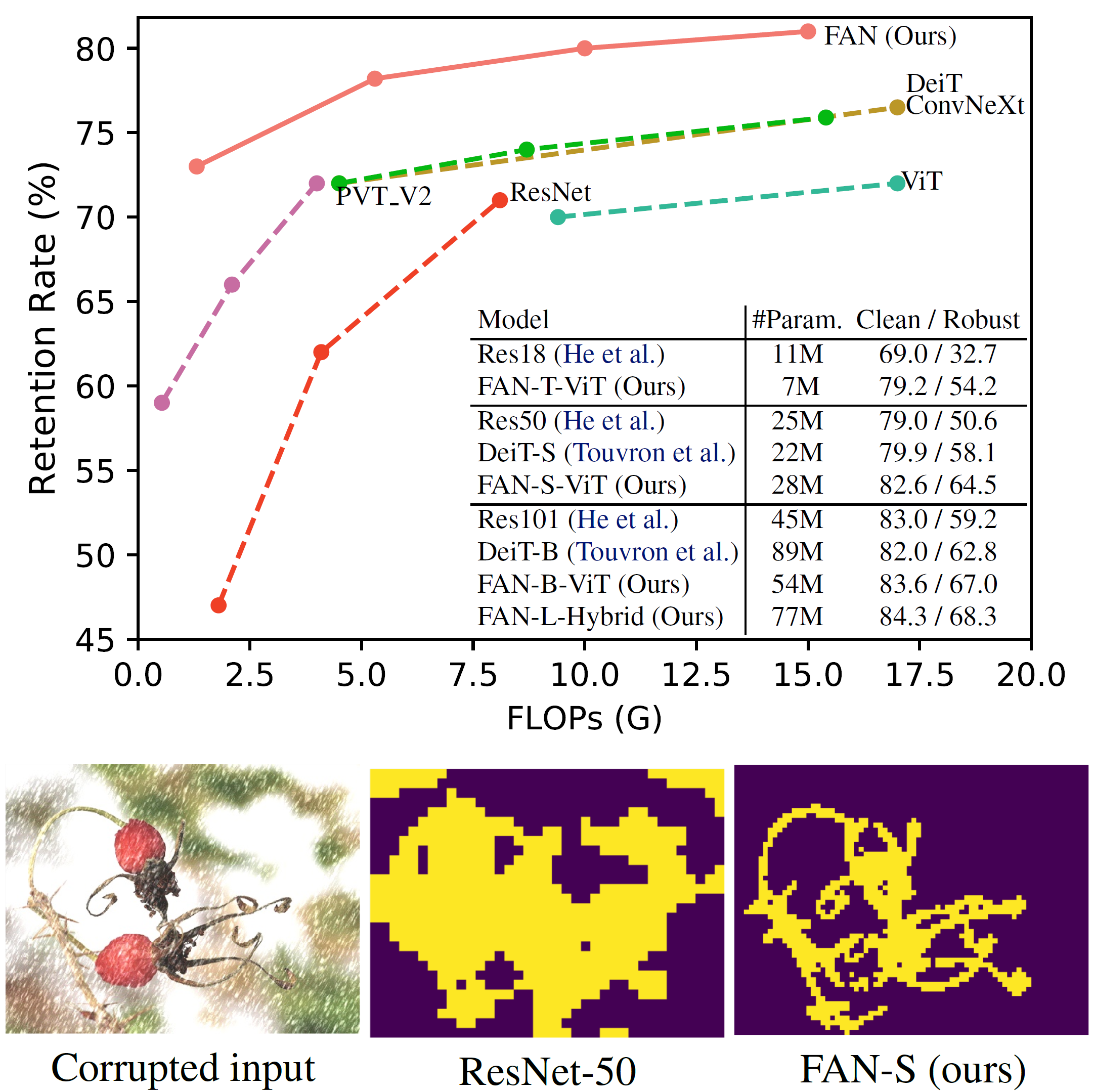
- By Jiashi Feng, ByteDance
- Code: https://github.com/NVlabs/FAN
They first find that ViT is more robust than CNN against common image distortions: motion blur, noise, snow.
Also, more Self-Attention (SA) blocks makes ViT more robust. Their work (FAN) is making ViT “fully attentional”, by adding a channel attention block in parallel with the last MLP in the self-attention block.
Result: ~10% more robust on segmentation/detection than ViT baseline, comparable param size, and attention visualization focus more on the contour of interesting objects. The FAN paper also provides an explanation of how ViT is more robust: it optimizes the Information Bottleneck, and implicitly filters out image noise.
Towards Compact and Tiny AI models on Edge
By Prof. Yiran Chen, Duke University
- NAS for efficient searching
- search space shrinking (Zhang et al. AAAI 20)
- Topology-aware NAS
- Graph embedding for NN candidates (Cheng et al. AAAI 21).
- They have a paper on predictor-based NAS for point cloud NN (Qi et al. 2017).
- Efficient 3D point-interact space, first and second-order point interaction. Reducing MAC and #param, baseline is KPConv. (WIP, arxiv)
- Structural sparsity: dynamic winners-take-all, a dropout technique to prune activations layerwise, low overhead on edge device. Mixed-precision with bit-level sparsity (H. Yang et. al, ICLR21), adding a LASSO on bitwidth during training.
- Next thing in NAS: interpretability.
Researching Efficient Networks for Hardware that Does not Exist Yet: physics and economics of ML co-design
Łukasz Lew, Google
- His talk high-lights the importance of quantization, custom numeric formats and measuring the cost of a system.
- How do data-centers choose ML accelerators? Performance/TCO (total cost ownership), basically electric bill.
- Google’s metric: Joules/inference, Joules/training to a given accuracy
- Quantization saves energy, it’s economically inevitable.
- Mixed Quantization, measuring the cost is difficult.
- ACE: arithmetic computation effort. (Zhang et al. CVPR22) It approximates the logical complexity of MAC operations, and is independent of today’s hardware technology (hence, future-facing). It generalizes to custom numeric formats.
- Interesting facts (very useful for motivation slides as well):
- ML hardware introduces more and more formats with their tradeoffs, like bfloat, NVIDIA’s multiple fp8 variants.
- We are using 15% of the hardware because of the dark silicon (cooling issue). ML chips are limited by power efficiency.
- Pay attention to bit-level sparsity, energy is only used when bits are flipped.
Thoughts
- Chicken and egg problem:
- ML hardware designers must use mostly exisiting ML models
- ML model designers must use existing hardware
A promising area: custom numeric formats.
Project Aria: Wearable Computing for Augmented Reality
Meta Reality Lab

There’s an Egocentric AI Gap for VR, AR & Wearables. Lots of data available, but they are not egocentric. Project Aria is a glass for data collection, to fill this gap. Unique challenges working with egocentric data: scene diversity + limited compute resources, limited sensing rate, noise from motion, multiple reference frames (dynamic settings), personal and privacy requirements.
Tackling Model and Data Efficiency Challenges for Computer Vision
BichenWu, Meta
Model Efficiency: the FBNet Family v1 to v5
- V1: differentiable NAS
- V2: differentiable can’t handle very large search space. Memory efficiency: sharing the same feature map with a mask.
- V3: joint architecture-train recipe search. Optimizer type, lr, decay, dropout, mix-up raito, ema, …. They switched to predictor-based NAS with a performance predictor.
- V4: skipped, it’s an internal model.
- V5: unified, scalable, efficient NAS for perception NAS. Previous NAS methods are designed for single tasks, introducing multitask search. Disentangle the search process from downstream tasks, with a proxy multi-task dataset. Simultaneously search for many tasks. New SOTA. (arxiv now)
Data Efficiency (less labeling)
Cross-domain adaptive teacher. The question is: can we train a model once and transfer to a new domain without annotating new data? E.g. can a model trained to localize real-life objects recognize their cartoon version? Solution: a teacher model using a pseudo label in the target domain, and a student model trained with unsupervised loss from the teacher model.
When Industrial Model Toolchain meets Xilinx FPGA
Jiahao Hu, Ruigao Gong, toolchain team, SenseTime Research
1st award of LPCV challenge, FPGA track
This is a presentation for their solution of the LPCV challenge.
- Setting
- Task: COCO object detection
- Hardware: Ultra96v2 + DPU overlay with Pynq
- Model: YOLOX-FPGA
- Toolchain
- Training framework: United Perception. United Perception is a training framework for multiple tasks. It also has plenty off-the-shelf training techniques.
- Quantization: MQBench for INT8 quantization
- Multi-platform deployment framework: NART (close source)
- Tips and tricks
- Training recipe: object365 dataset pretrain + distillation
- They optimized the post processing process by havng a C implementation for NMS, signoid, and decoder, resulting in a 74% reduction in post processing time compared with Python implementation.
- Use multithreading for pre- and post-process, so the inference is pipelined.
Their training framework and inference code is open source:
https://github.com/ModelTC/United-Perception
https://github.com/ModelTC/LPCV2021_Winner_Solution
Thoughts
Their compilation flow is onnx -> xmodel -> DPU instruction. This process happens in Vitis, and it seems that Vitis has a much better operator support on DPU now.
There’s a live question about deploying vision transformers on edge devices. Sensetime thinks it’s still a long way to go.
Embedded Vision Workshop
Workshop link: website
MAPLE-EDGE: A Runtime Latency Predictor for Embedded Devices
Paper link: cvpr
MAPLE-Edge is an edge device-oriented extension to MAPLE, designed specifically to estimate the latency of neural network architectures on unseen embedded devices. MAPLE-Edge trains a LPM-based (Linear Probability Model) hardware-aware regression model that can effectively estimate architecture latency. To do this, it trains the LPM on a dense hardware descriptor made up of CPU performance counters, in conjunction with architecture-latency pairs. In the data collection stage, MAPLE-Edge uses an automated pipeline to convert models in NAS-Bench-201 to their optimized counterparts, deploy it to the corresponding target device, and profile inference.
MAPLE-X: Latency Prediction with Explicit Microprocessor Prior Knowledge
Baseline: meta-learning based latency prediction model (HELP). This seems interesting as well.
Hypothesis: NN arch latency rankings are highly similar across devices.
The setting is NAS. The prior knowledge is latencies measured on a source device. The goal is to predict latencies on a target device. With the hypothesis, we can only measure a few nn archs on the target device and assign the rest with a prior according to their ranking.
Main Conference
Opening Remark
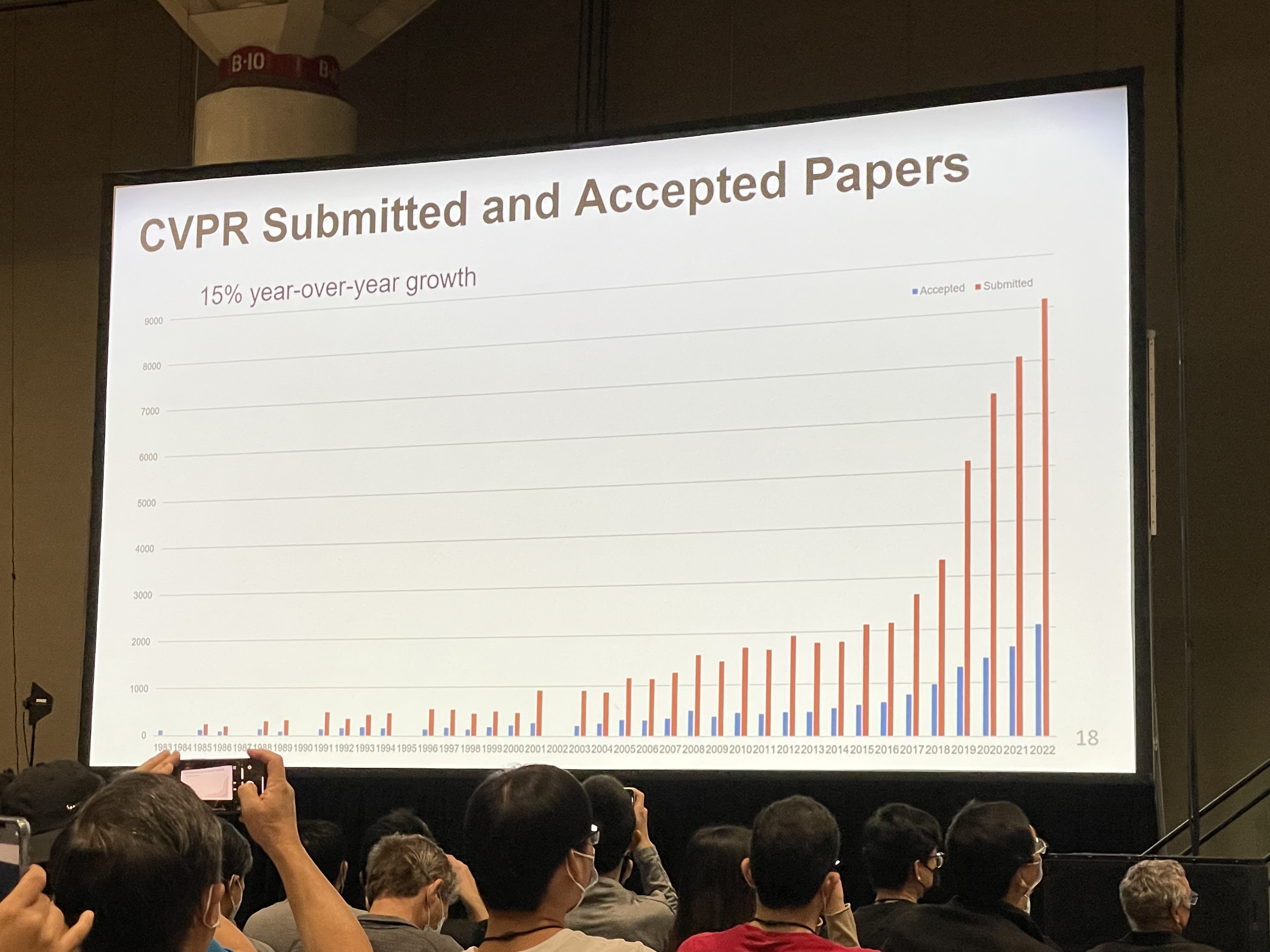
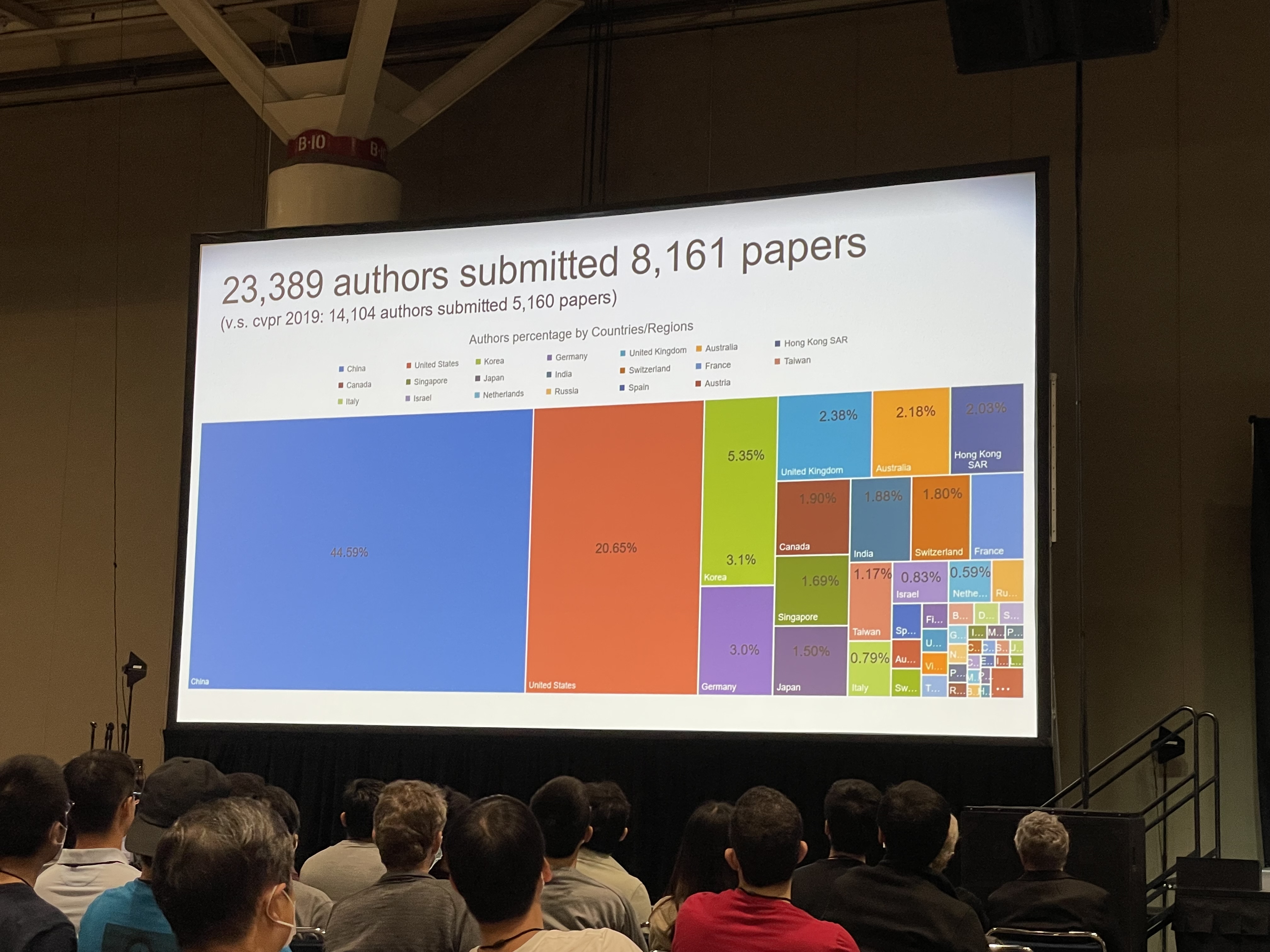
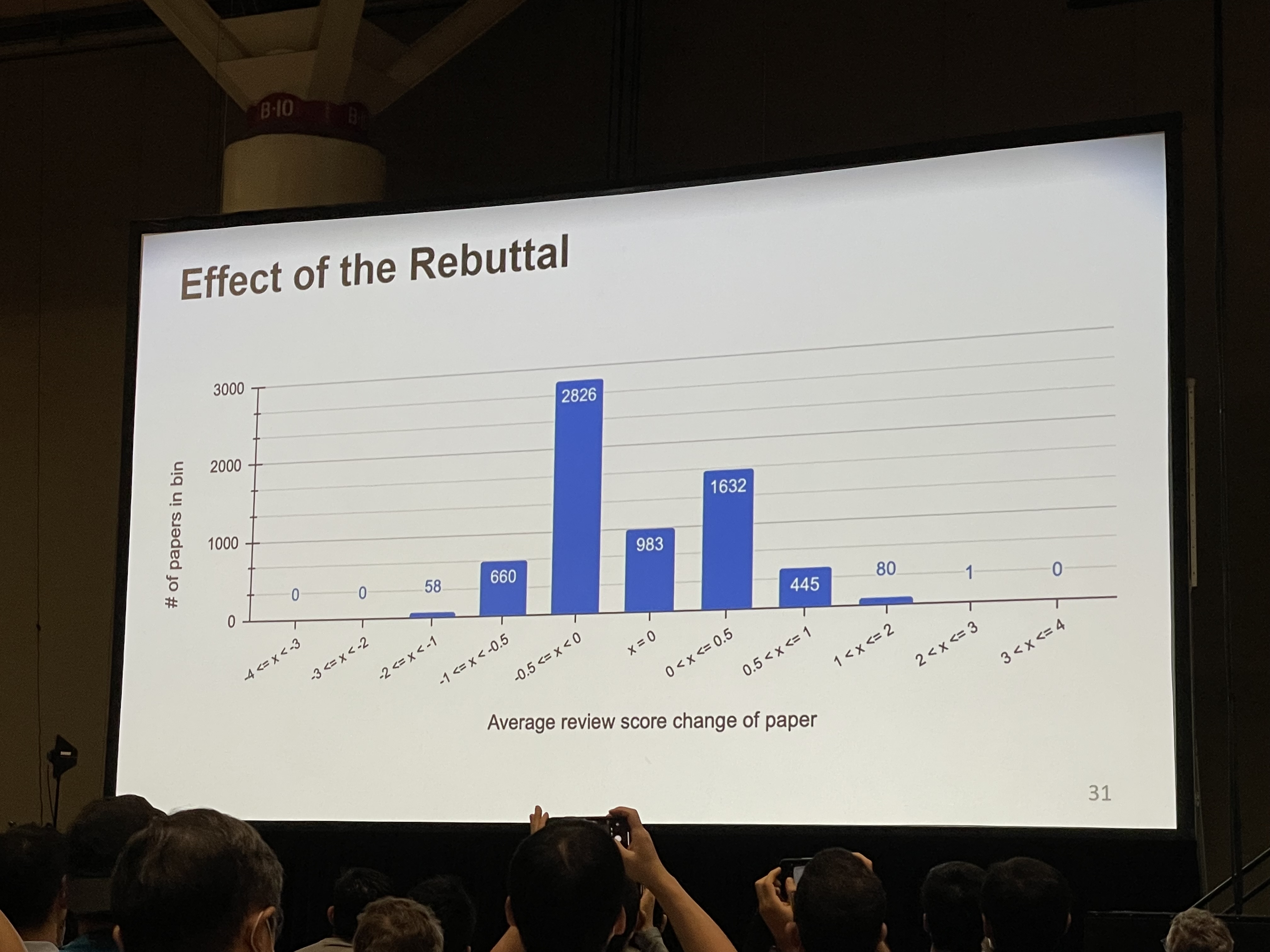

Some interesting statistics:
- 8,161 paper submission, 2,064 are accepted.
- 5,641 in-person attendees, 4340 virtual attendees.
- Exponential growth of submissions.
- Rebuttal effectively increases the chance of getting accepted.
Our Presentation

I presented at the first poster session on Tuesday. Our work is about how to improve transformer’s generalization ability on 3D voxel data with a codebook self-attention and explicit geometric guidance. About 20 to 30 people stopped by during the poster session, and a few after the session.
Here are some questions I got during the presentation:
- How do you design the sparse pattern and choose the dilation? (asked most frequently)
- How is
w(the weight of the prototypes) generated? - Have you considered learning the sparse pattern during training?
- Can we use this codebook design for generative models like color/material manipulation?
- Voxel size? Are you using MinkowskiEngine for implementation?
- How long does it take to train a model?
- Future plan for this project?
Paper Highlights
Here I highlight a few papers that I find interesting or worth noting, and I categorize them into these groups: explanable vision, efficiency, and 3D scene understanding.
Explanable Vision
NLX-GPT: A Model for Natural Language Explanations in Vision and Vision-Language Tasks
- Presentation: Oral
- Paper: cvf
- Institution: Vrije Universiteit Brussel
- PI: Nikos Deligiannis
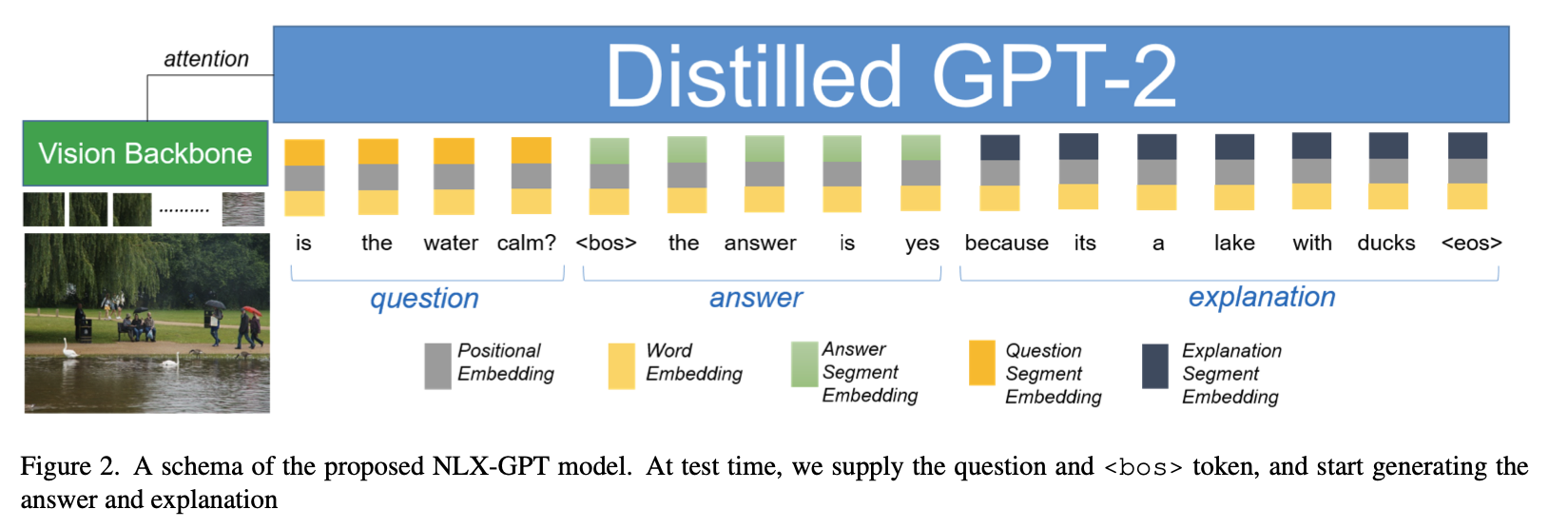
Use Vision-Language models to explain the decision-making process of a black box system via generating a natural language sentence.
Deep Spectral Methods: A Surprisingly Strong Baseline for Unsupervised Semantic Segmentation and Localization
- Presentation: Oral
- Paper: cvf
- Institution: University of Oxford
- PI: Andrea Vedaldi
This work combines self-supervised learning and traditional graph semantic theory on semantic segmentation and localization tasks. The result outperforms SOTA self-supervised models by a large margin.
3D Scene Understanding
Stratified Transformer for 3D Point Cloud Segmentation
- Presentation: Poster
- Paper: cvf
- Institution: CUHK, HKU, SmartMore, MPI Informatics, MIT
- PI: Jiaya Jia
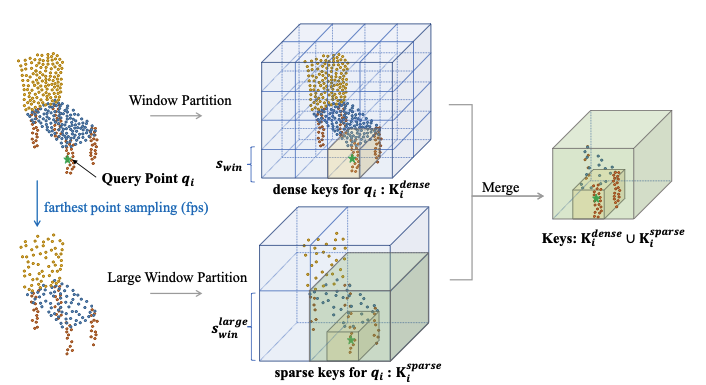
A stratified sampling strategy for point cloud transformers that densely samples local points and sparsely samples distant points. The results demonstrate better generalization ability.
Point Density-Aware Voxels for LiDAR 3D Object Detection
- Presentation: Poster
- Paper: cvf
- Institution: University of Toronto
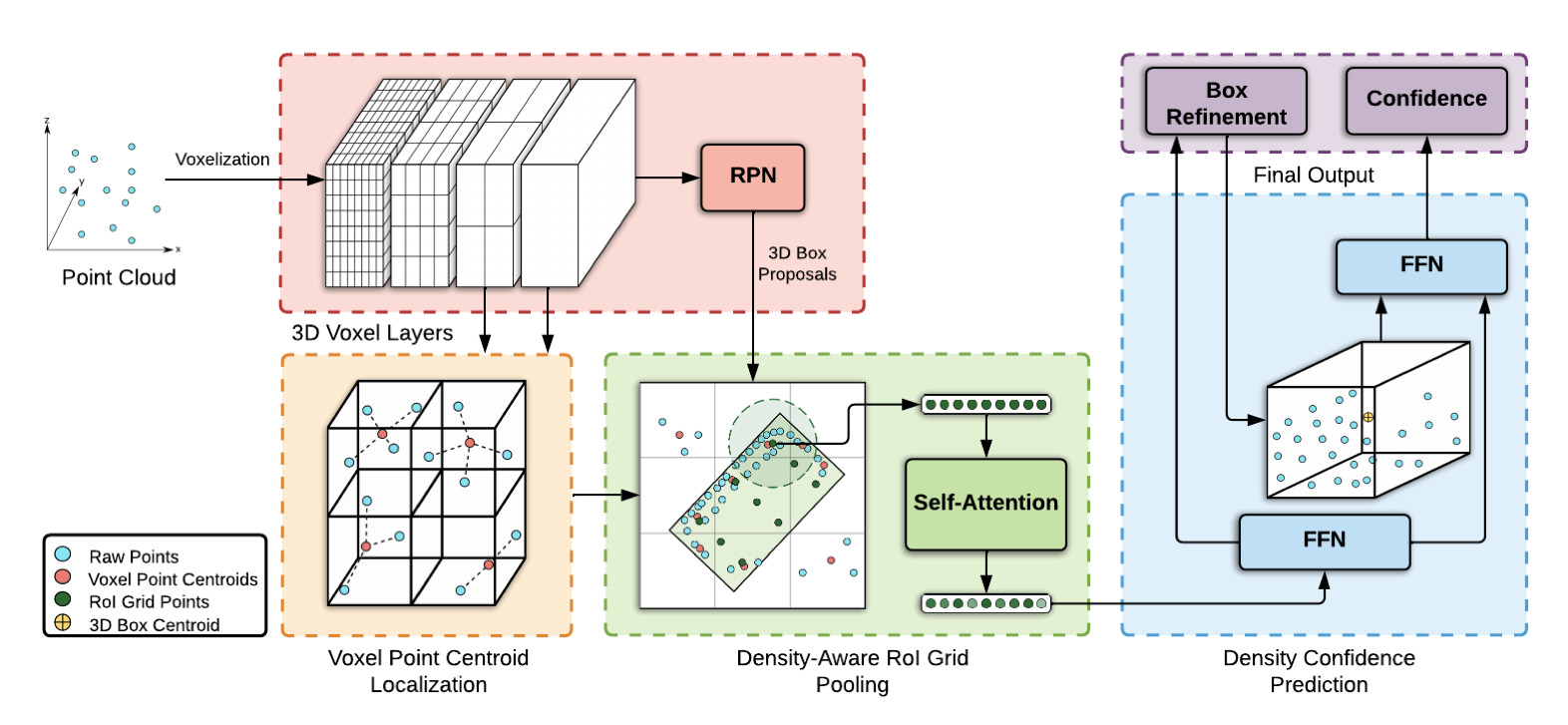
A LiDar 3D object detecture architecture that takes point density variation into account during ROI pooling. It achieves the new SOTA on the Waymo Open Dataset.
Domain Adaptation on Point Clouds via Geometry-Aware Implicits
- Presentation: Poster
- Paper: cvf
- Institution: Zhejiang University, Stanford and Peiking University
- PIs: He Wang, Youyi Zheng, Leonidas Guibas
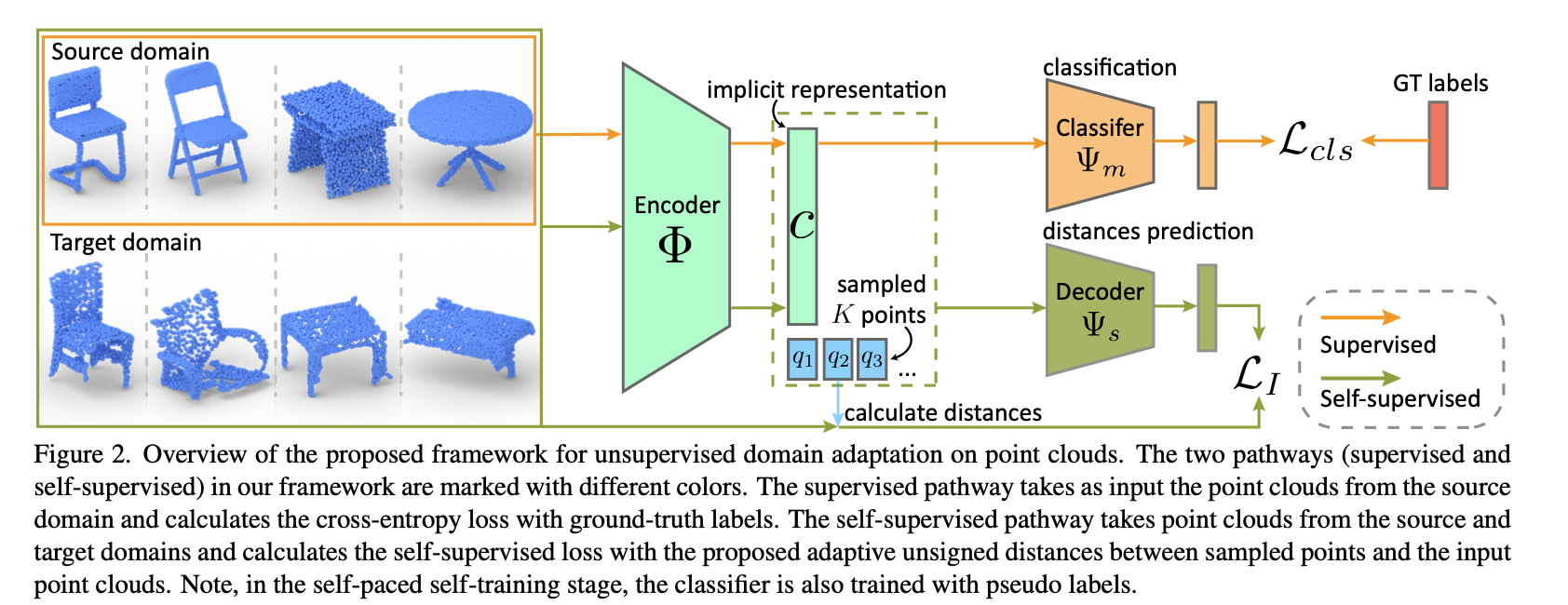
Point cloud data of the same object can have significant geometric variation when captured by different censors or using different procedures. This work proposes an unsupervised domain adaptation method leveraging the gemoetric implicits.
Efficiency
It’s All in the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
- Presentation: Oral
- Paper: cvf
- Institution: Yonsei University
- PI: Jinho Lee
Zero-shot quantization (or data-free quantization) is quantizing a neural network without access to any of its training data. This is done by taking information from the weights of a full-precision teacher network to compensate the performance drop of the quantized network.
MiniViT: Compressing Vision Transformers with Weight Multiplexing
- Presentation: Poster
- Paper: arxiv
- Institution: Microsoft
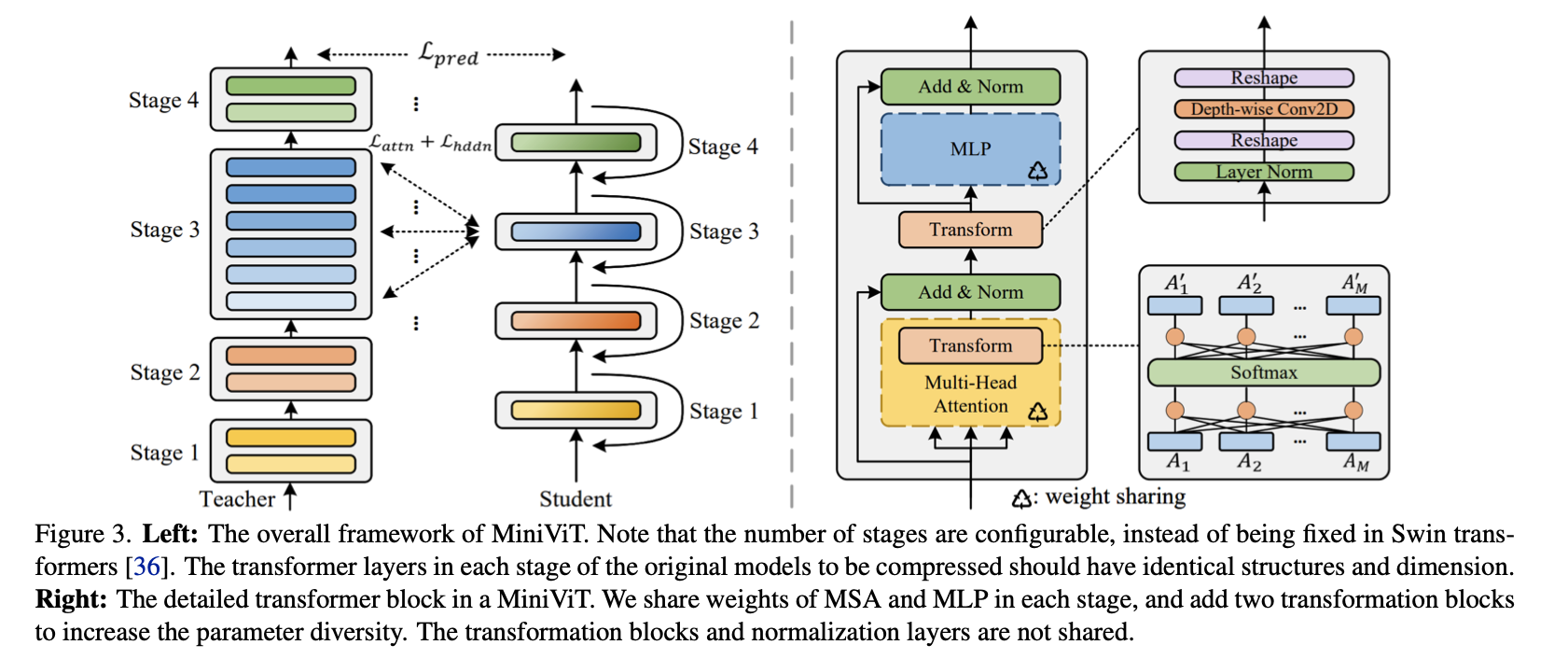
ViT has good performance but is computationally expensive. This work compresses ViT by multiplexing (sharing) weights of consecutive transformer blocks.
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
- Presentation: Poster
- Paper: cvf
- Institution: Tsinghua University, MEGVII
- PI: Guiguang Ding
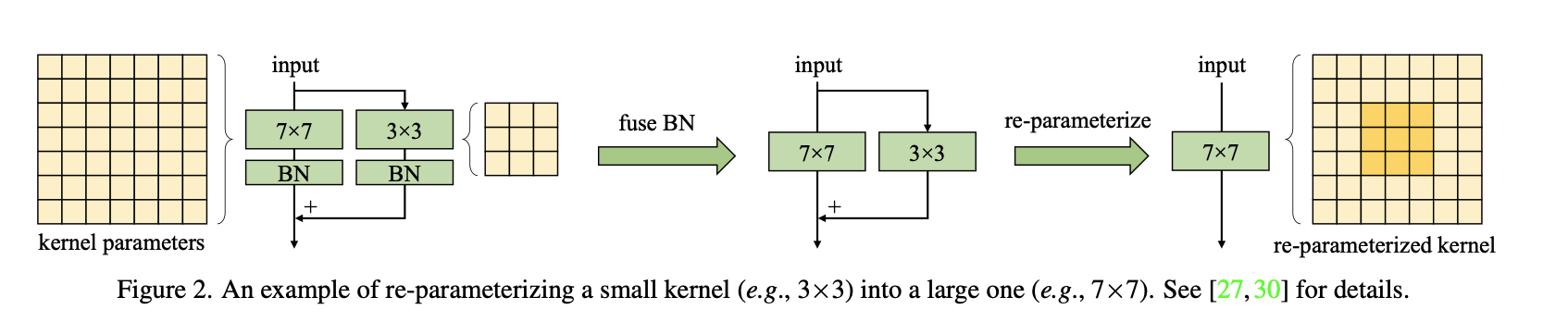
This paper proposes RepLKNet to scale ConvNet kernels to 31x31 with reparameterization.
A-ViT: Adaptive Tokens for Efficient Vision Transformer
- Presentation: Poster
- Paper: arxiv
- Institution: NVIDIA
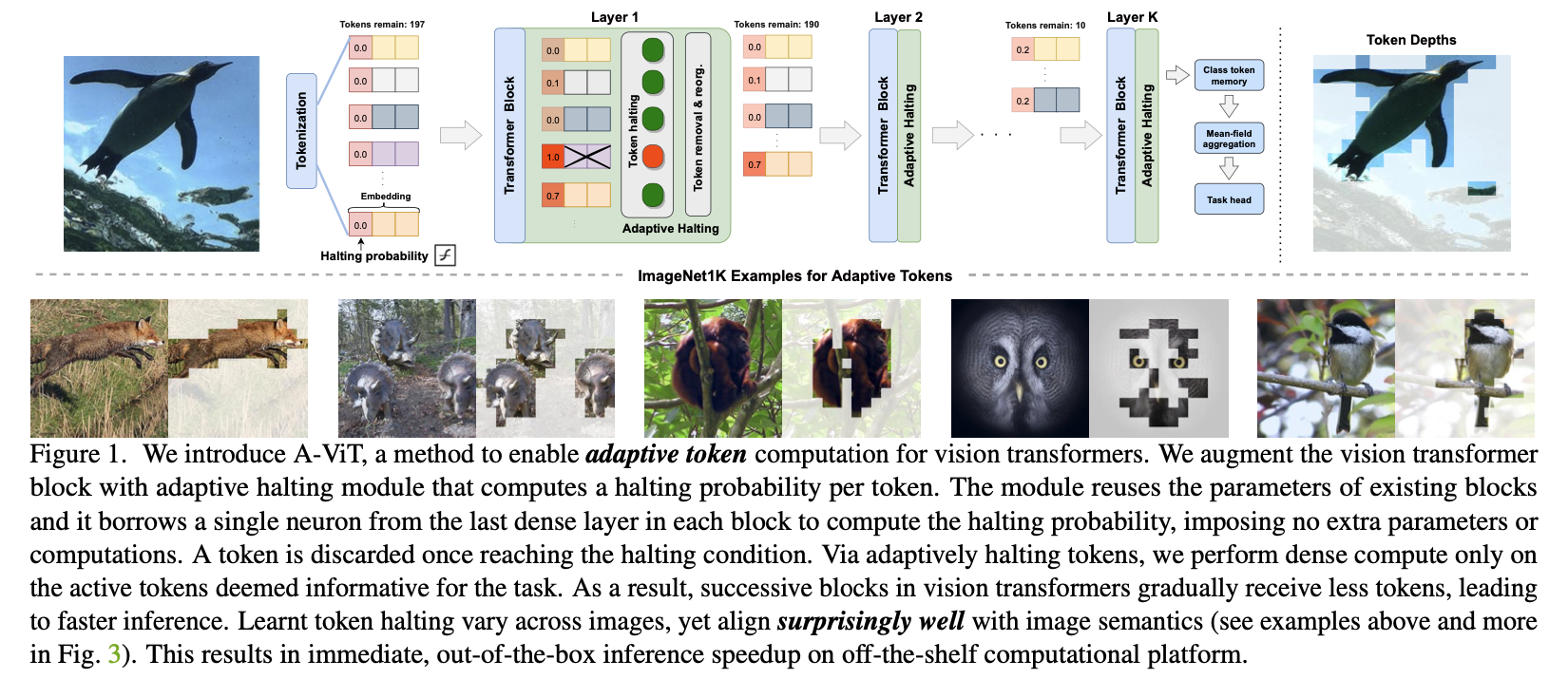
Let ViT learns which image patches to preserve, discarding redundant spatial tokens to achieve higher efficiency. The loss is designed to balance the accuracy-efficiency trade-off.
The Ongoing Debate of ConvNet or Transformer
A ConvNet for the 2020s
- Presentation: Oral
- Paper: cvf
- Institution: Berkeley and FAIR
- PIs: Trevor Darrell, Saining Xie
This work is aimed to test the limit of a pure ConvNet. They gradually “modernize” a standard ResNet towards the design of a vision Transformer, and discover several key components that contribute to the performance difference:
- Stage Compute Raio
- Non-overlapping Conv, “to pachify”
- Use depthwise convolution
- Inverted bottleneck
- Large kernel sizes
- Replacing ReLU with GELU
- Fewer activation and normalization
- Substitue BN with LN
- Separate downsampling layer from basic block
Demos
CVPR features a huge demo event. Companies and sponsors showcase their product or research work with actual demos and give out gifts. Here are some pictures of the demos:







Tesla’s cyber truck is a lot larger than I imagined.
Student Activity: Speed Mentoring
Students attending CVPR has a chance to participate “speed mentoring”. Each table sits around students with one empty seat, and mentors will rotate between tables. Mentors are professors and senior researchers from the industry. The students are free to ask about any questions.
Tesla AI Event
Companies would invite authors of relevant field to their exclusive events during CVPR. I was fortunate enough to be invited to Tesla’s AI event.

Elon Musk connected with the live audience and did an AMA. The head engineers at Tesla introduce their vision-first approach on self-driving. I also had a chance to test drive a prototype Tesla Modle 3 on New Orlean’s streets.
Special Event at Mardi Gras World
This is CVPR’s reception event happening in parallel with Tesla’s event. I didn’t attend this event but here is a video from a friend who did.
New Orleans
The Streets and the Mississippi River







New Orleans is a beatiful city, and it’s much hotter and humid than I expected. During the day it’s about 38 degree with 70% humidity. During the conference I visited the French Quarter and walked along the Mississippi River.
Food









The seafood in New Orleans is supreme. I especially enjoyed the seafood gumbo and the crawfish pasta. The Gus world-famous fried chicken is also delicious, make sure to try it if you are in New Orleans.