Loop optimization in Vivado HLS.
What is II?
II means initiation interval.
For a function, II is the number of clock cycles before it could accept new inputs and is generally the most critical performance metric in any system.
For a loop, II is the number of clock cycles before the next iteration of a loop starts to process data.
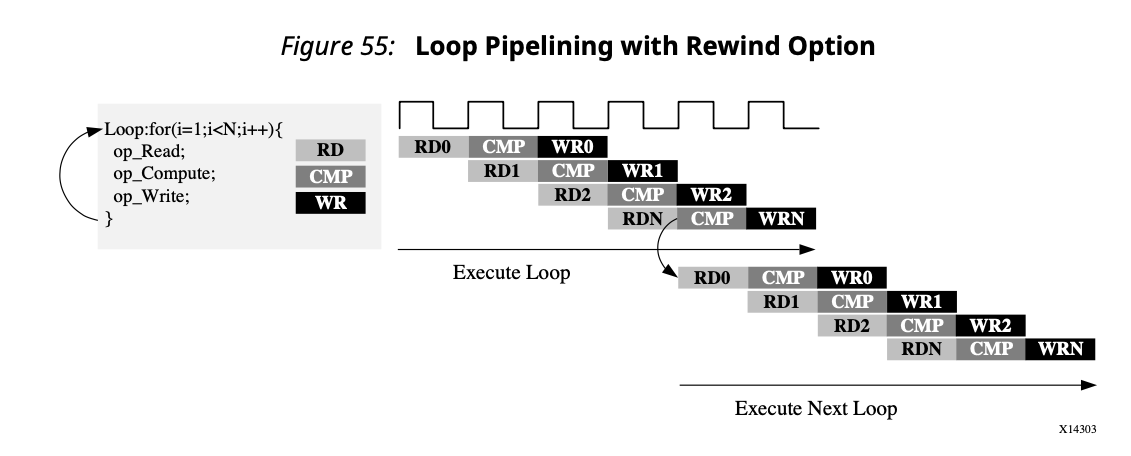
Loop Pipelining

Although we are already familiar with “pipelining”, this figure still gives a great example for “II” and loop latency.
There are some more details about loop pipelining. One thing worth noticing is that when a loop is called multiple times, there could be a thing called io “bubble” happening:

This means that when the loop finishes executing, the next read and write won’t start until the loop is called again, even though II=1. So, if there are loops that are called multiple times, we can identify them and allow each call to overlap to remove the bubble. This is called rewind.
Loop Unrolling
Loop unrolling is to trade performance (latency, throughput) with resources.
By default, loops are kept rolled in Vivado HLS. These rolled loops generate a hardware resource which is used by each iteration of the loop.
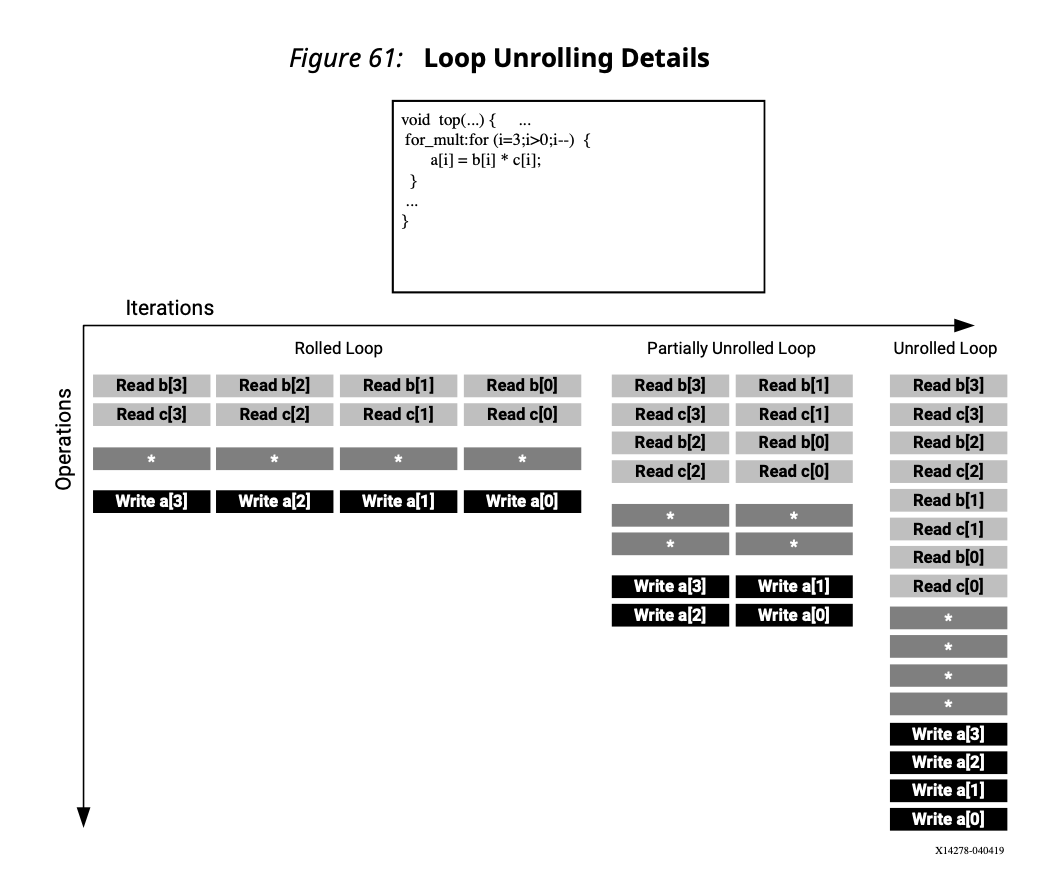
Rolled Loop
When the loop is rolled, each iteration is peformed in seperate clock cycles. This implementation takes four clock cycles, only requires one multiplier and each block RAM can be a single-port block RAM.
Partially Unrolled Loop
We can partially unroll a loop by specifying a unroll factor. In this example, we are setting unrolling factor = 2. This implementation requires two multipliers and a dual-port RAMs to support two reads or writes to each RAM in the same clock cycle. This implementation does however only take 2 clock cycles to complete.
Unrolled Loop
If the loop is fully unrolled, it uses 4 multipliers and requires the ability to perform 4 reads and 4 writes at the same time (we can achieve this with array partitioning). This uses more computation and storage resources but only take 1 clock cycle to complete.
Array Partitioning

A common issue in pipelined loop is memory conflict. Arrays in HLS are implemented as Block RAMs. If there are two accesses to the same array in the loop body, it will need two read operation through the same memory port. So II becomes 2.
How do we solve this? The idea is to break one array into multiple parts, each part implemented as a BRAMs, so that we can access them at them same time.
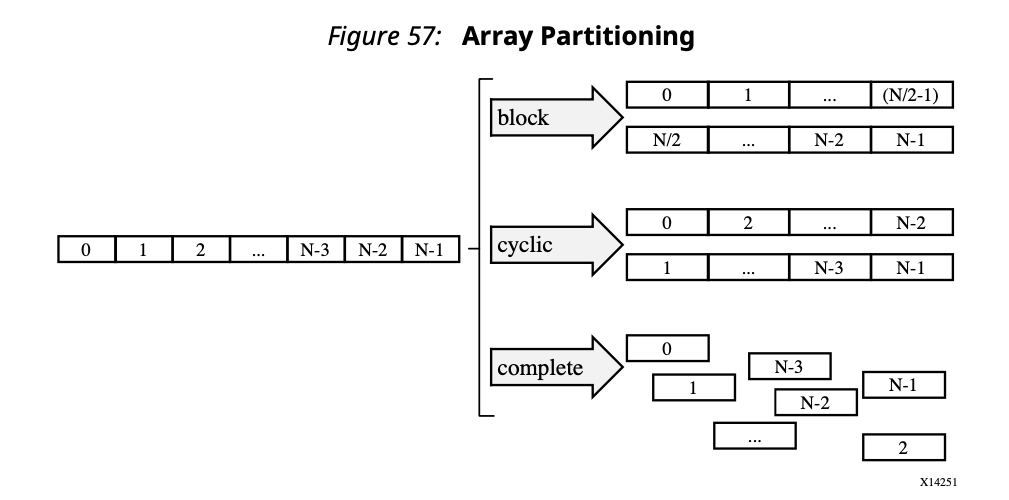
There are three fashions of array partitioning:
- Block: the original array is split into equally sized blocks of consecutive elements of the original
- Cyclic: the original array is split into equally sized blocks interleaving the elemetns of the original array.
- Complete: the default operation is to split the array into its individual elements. This corresponds to resolving a memory into registers.
References
Loop pipelining and loop unrolling
ug902-vivado-high-level-synthesis.pdf