Deep learning methods for 3D scene understanding, particularly focused unsupervised methods.
3D Datasets
Data Representations
- Multiview images: multiple 2D images of the same object from different angles.
- Depth map
- Voxel: volumetric occupancy
- Point cloud
- Polygon mesh
- Functions as implicit representation
ScanNet Dataset
- Scene: Indoor

ScanNet is a richly-annotated RGB-D video dataset. It has camera poses information, surface reconstruction, sementic segmentation labels.
Data Formats
*.ply Reconstructed surface mesh file
This is binary PLY format mesh with +Z axis in upright orientation.
*.sens RGB-D sensor stream
This is binary format with per-frame color, depth, camera pose and other data.
*.segs.json Surface mesh segmentation file
1 | { |
Usage
Check SpatioTemporalSegmentation/lib/pc_utils.py.
To load a mesh file:1
2
3
4
5
6
7
8
9from plyfile import PlyData
def load_ply(self, index):
filepath = self.data_root / self.data_paths[index]
plydata = PlyData.read(filepath)
data = plydata.elements[0].data
coords = np.array([data['x'], data['y'], data['z']], dtype=np.float32).T
feats = np.array([data['red'], data['green'], data['blue']], dtype=np.float32).T
labels = np.array(data['label'], dtype=np.int32)
return coords, feats, labels, None
Tools
Minkowski Engine
The Minkowski Engine is an auto-differentiation library for sparse tensors. It supports all standard network layers such as convolution, pooling, unpooling, and broadcasting operations for sparse tensors.
3D voxel feature maps are often sparse. Minkowski Engine generalizes the definition of 3D sparse convolution and provide implementation support for it. The sparse convolution is defined as:
This definition does not limit the shape of the kernel.
is the current convolution center. is a set of offsets that define the shape of a kernel, centered at . , are predefined input and output coordinates of sparse tensors.
Minkowski Engine uses COO format (Coordinate list) to store sparse tensors, meaning that, it stores a list of non-zero coordinates and corresponding features:
Concepts
Coordinate Manager
Because the feature map is sparse, we need to dynamically find neighbors between non-zero elements. Minkowski Engine has a mechanism called coordinate manager that caches and reuses calcualted neighbor coordinates. When a MinkowskiEngine.SparseTensor is initialized, a coordinate manager is also created. The coordinate manager can be accessed with MinkowskiEngine.SparseTensor.coords_man, and it can be shared with a new sparse tensor by providing it as an argument during initialization.
Channel
The channel number in 3D context is the length of the feature vector.
Paper Digests
PointContrast: Unsupervised Pre-Training for 3D Point Cloud Understanding
- Authors: Saining Xie, Jiatao Gu, Demin Guo, Charles R. Qi, Leonidas Guibas, Or Litany
- Venue: ECCV 2020
- Institution: Facebook AI & Stanford
Motivation
To design a full pipeline for 3D unsupervised pretraining: view generation methods, downstream task compatible backbone, contrastive loss design. Previous work (pretraining on ShapeNet) doesn’t work because of two reasons: source & target data domain gap and lack of point-level representation.
Methodology
PointContrast Pipeline: contrasting at point-level
- Given point cloud
, generate two views and that are aligned in the same world coordinates. - Compute the correspndence mapping
between these two views. If then points and are a matched pair. - Randomly sample two geometric transformations
, (translation, rotation, scaling), and apply each to the paired points. - Compute output point feature
and . - Backprop to update NN with point-wise contrastive loss.
Contrastive Loss Design
The intuition of contrastive loss is to seperate negative pairs and pull together positive pairs as much as possible.
, are the features of matched points. : Euclidean distance. and are positive/negative margins, they are hyperparameters. is a randomly sampled set of non-matched (negative) points.
hardest sample means the closest point in thenormalized feature space. Because the closest negative point in the feature space is the hardest to separate.
PointInfoNCE is derived from InfoNCE. InfoNCE treat contrastive learning as classification problem, thus implemented with cross-entropy loss.
, annealing temperature, the output distribution goes “flat”, i.e. positive pair become less distinguishable. the output distribution goes sharp, i.e. positive pair becomes more distinguishable.
Backbone Design
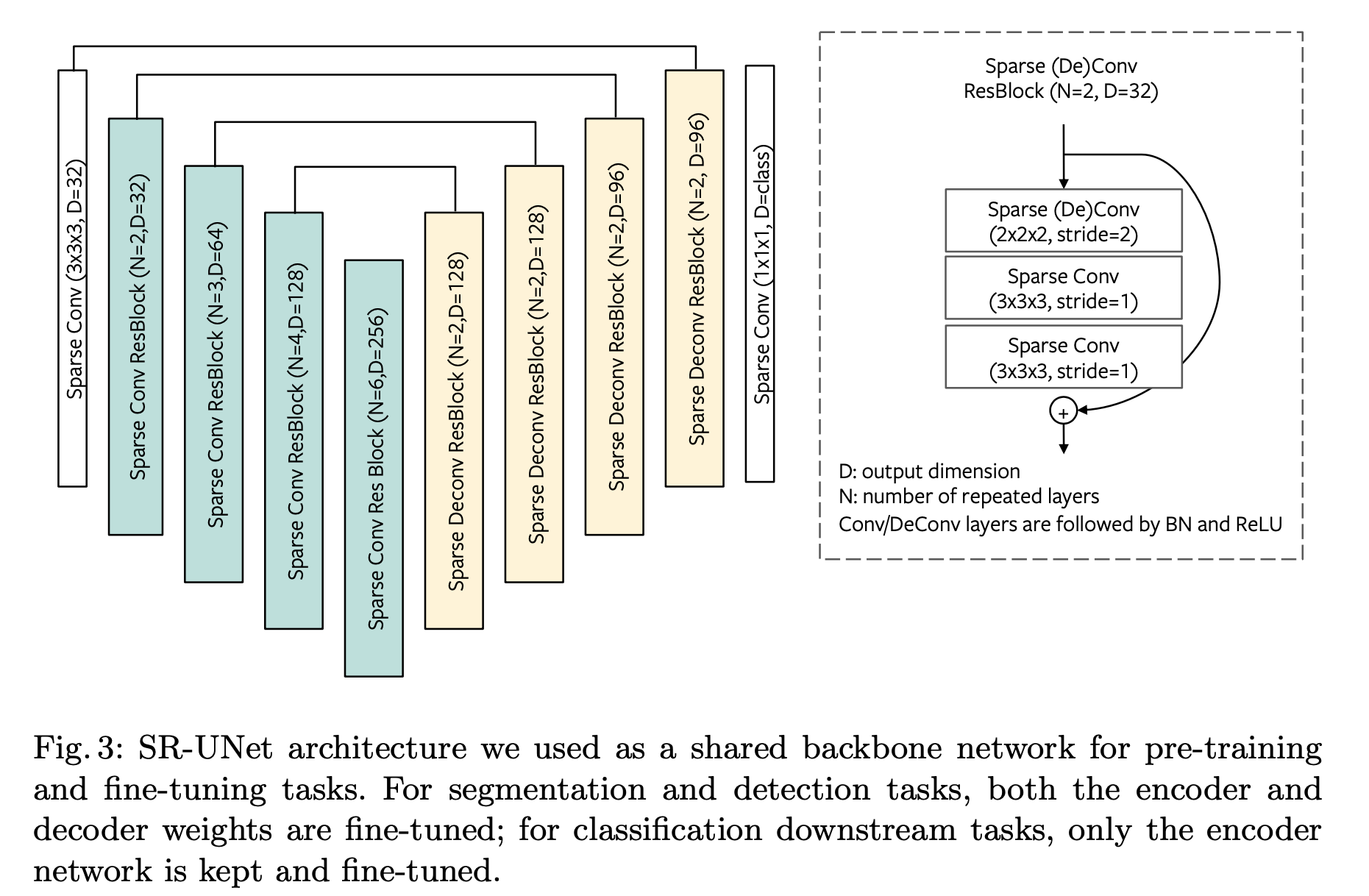
Conclusions
Why Pretraining with ShapeNet dataset is not useful?
- Domain gap between source and target dataset: alignment, scene context …
- Point-level representation matters: local geometric feature is critical for 3D tasks
PointInfoNCE Loss outperforms Hardest-Contrastive Loss
The advantages of fully-convolutional design
- Don’t have to crop objects out from scene context as done in previous works.
- Enables “point-level metric learning”.
Questions and Answers
What is “view” and how is it generated?”
View is partial point cloud seen from different viewpoints. We can generate two views by cropping them from a complete point cloud. “Aligning two views in the same world coordinates” means to register them, i.e., find the common matched points.
How do we know the mapping between output features?
The SRUNet’s output point cloud has the exact same coordinates with its input (just like segmentation). So we can use the input points’ mapping to map features in the output sparse tensors.
Resources
Paper Lists
Blog Posts
3D related: View things from another dimension - Posted by Tianchen